From the naturalistic perspective, all diversity of life forms evolved from a “simple” organism such as bacteria which diverged and vastly improved over time. Over the eons of time many generations advanced from single cell organisms to multi-cellular animals, finding the pinnacle of human beings a few million years ago. In 1972, geneticist Susumu Ohno identified that the bulk of the DNA genome (98% of it) was found not to be involved in protein coding. He quickly concluded that the majority of the genome that was not used for protein coding was “junk DNA”. He (ignorantly) reasoned from his Darwinian evolutionary perspective, that the 98% non-protein coding region were mere vestiges or remnants from past errors and mistakes– it was the junk that was left behind. Ohno’s claim has been called “the greatest blunder in the history of biology” and has been firmly debunked.
In 2015, Francis Collins, the director of the National Institutes of Health, made a comment that revealed just how far off the comment of Ohno’s regarding “junk DNA” was in light of recent research. Collins stated, “We don’t use that term anymore, it was pretty much a case of hubris (ignorance) to imagine that we could dispense with any part of the genome—as if we knew enough to say it wasn’t functional…(Pointing out that what DNA scientists once thought as junk) turns out to be doing stuff.” 1
“The failure to recognize the full implications of information derived from non-coding DNA may well go down as one of the biggest mistakes in the history of molecular biology.”
Gibbs, W. W. 2003. The Unseen Genome, Gems among the Junk. Scientific American. 289 (5): 26-33.
Today over 80% of the genome has identified function and…it is expected that 100% will be discovered as functional.”
Guliuzza, Randy J P.E. M.D. “Major Evolutionary Blunders: Evolutionists Strike Out with Imaginary Junk DNA, Part 2” Apr 2017
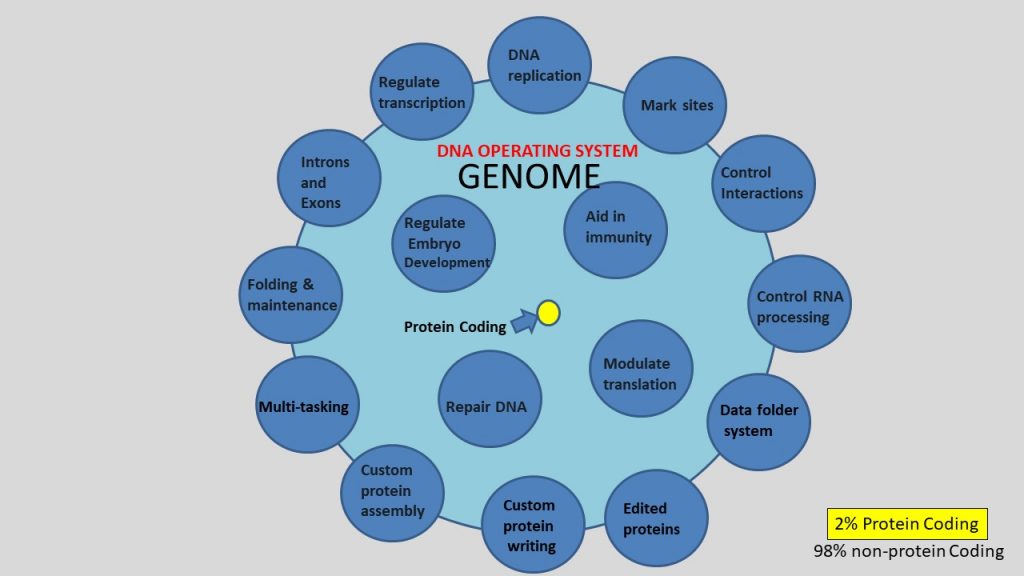
Similar to the operating software of computers, the non-coding portion of the DNA genome complete a dizzying array of information related tasks and responsibilities.
“Scientific discoveries have shown that non-coding regions of the genome…(1) Regulate DNA replication, (2) Regulate transcription, (3) Mark sites for programmed rearrangements of genetic material, (4) Influence proper folding and maintenance of chromosomes, (5) Control interactions of chromosomes, (6) Control RNA processing, editing, and splicing, (7) Modulate translation, (8) Regulate embryological development, (9) Repair DNA, (10) Aid in immunity,a (11) Introns and Exons mark the start and end of sections of the genomes…for specialized protein coding, (12) Specialized protein assembly instructions…are stored in overlapping and/or multiple regions of the genome that can be combined and edited with “spliceosomes” and “editosomes”.b
Meyer, Stephen C. “Signature in the Cell” (a) p. 407 & (b) p. 462
“Indeed, as a result of the overlapping genetic messages and different modes of information processing, the specified information stored in DNA is now recognized to be orders of magnitude greater than initially thought…”
Meyer, Stephen C. “Signature in the Cell” a. page 462
Of course the genome does display elements of damage from past transcriptions, deletions, mutations, and the like, but these are not “junk” nor are they what would be expected by Darwinian evolution. Evolution imagines a continual improvement and diversification of species caused by the mechanism of spontaneous random mutations adding new information and beneficial characteristics into the genome to later be locked-in by natural selection. However, this is not what the genome reveals about such mutations. The remnants of past errors and deletions reveal a degradation and degeneration of broken or lost genetic material. Spontaneous mutations are not “adding up” or “improving” species at all…rather, genetically we are falling apart. Genetically we are becoming worse off with each new generation–quite the opposite of what the theory of evolution proposes.
“The genome does display evidence of past viral insertions, deletions, transpositions, and the like, much as digital software copied over and over again accumulates errors.”
Meyer, Stephen C. “Signature in the Cell” p 461
More related blogs: MUTATION MEANS TWO WILDLY DIFFERENT THINGS: FUNCTION AND ERROR, DIVERSITY “NATURAL SELECTION” ARE FUNCTIONS OF DNA (ALLELES), EVEN A MERE 2 AMINO ACID CHANGE INSURMOUNTABLE FOR EVOLUTION, GENETIC ENTROPY REVEALS DEVOLUTION,
1 Zimmer, C. Is Most of Our DNA Garbage? New York Times. Posted on nytimes.com March 5, 2015, accessed January 20, 2017.
2 https://www.guru99.com/operating-system-tutorial.html
3 Meyer, Stephen C. “Signature in the Cell” p. 461-462
